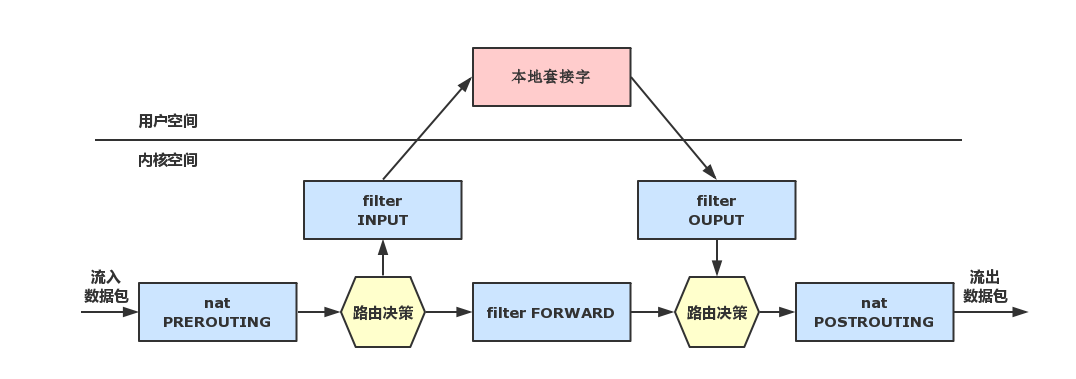
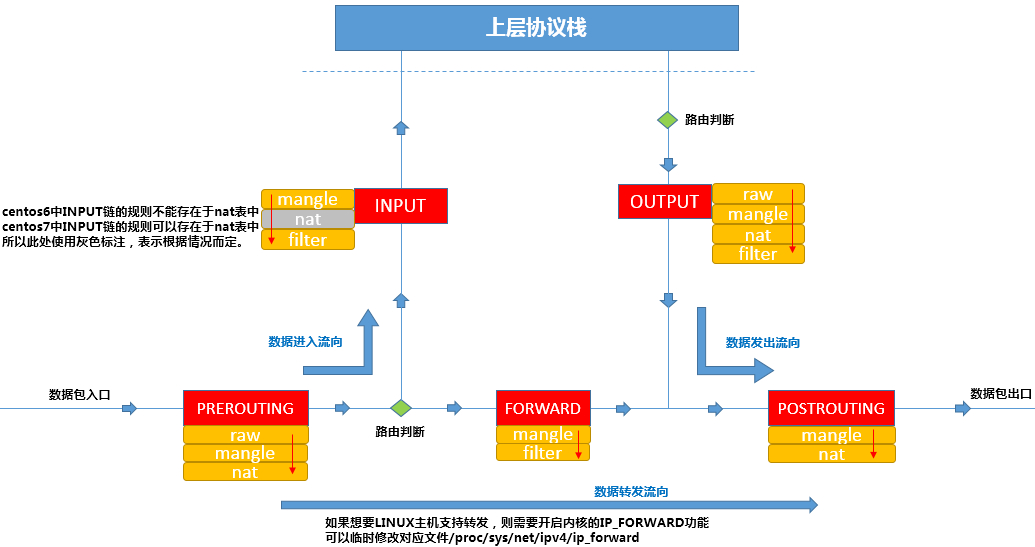
Linux 系统在内核中提供了对报文数据包过滤和修改的官方项目名为 Netfilter,它指的是 Linux 内核中的一个框架,它可以用于在不同阶段将某些钩子函数(hook)作用域网络协议栈。Netfilter 本身并不对数据包进行过滤,它只是允许可以过滤数据包或修改数据包的函数挂接到内核网络协议栈中的适当位置。这些函数是可以自定义的。
选项与参数: -m :一些 iptables 的外挂模块,主要常见的有: state :状态模块 mac :网络卡硬件地址 (hardware address) --state :一些封包的状态,主要有: INVALID :无效的封包,例如数据破损的封包状态 ESTABLISHED:已经联机成功的联机状态; NEW :想要新建立联机的封包状态; RELATED :这个最常用!表示这个封包是与我们主机发送出去的封包有关
#ICMP 封包规则的比对:针对是否响应 ping 来设计
iptables -A INPUT [-p icmp] [--icmp-type 类型] -j ACCEPT
# For keepalived: # allow vrrp -A INPUT -p vrrp -j ACCEPT -A INPUT -p igmp -j ACCEPT # allow multicast -A INPUT -d 224.0.0.18 -j ACCEPT
# Drop packets from spoofed networks -A INPUT -s 169.254.0.0/16 -j DROP #-A INPUT -s 10.0.0.0/8 -j DROP #-A INPUT -s 127.0.0.0/8 -j DROP -A INPUT -s 224.0.0.0/4 -j DROP -A INPUT -d 224.0.0.0/4 -j DROP -A INPUT -s 240.0.0.0/5 -j DROP -A INPUT -d 240.0.0.0/5 -j DROP -A INPUT -s 0.0.0.0/8 -j DROP -A INPUT -d 0.0.0.0/8 -j DROP -A INPUT -d 239.255.255.0/24 -j DROP -A INPUT -d 255.255.255.255 -j DROP
# Drop Invalid packets -A INPUT -m state --state INVALID -j DROP #-A FORWARD -m state --state INVALID -j DROP -A OUTPUT -m state --state INVALID -j DROP
# Drop Bogus TCP packets -A INPUT -p tcp --tcp-flags SYN,FIN SYN,FIN -j DROP -A INPUT -p tcp --tcp-flags SYN,RST SYN,RST -j DROP
-A INPUT -p icmp --icmp-type echo-reply -j ACCEPT -A INPUT -p icmp --icmp-type destination-unreachable -j ACCEPT -A INPUT -p icmp --icmp-type redirect -j ACCEPT -A INPUT -p icmp --icmp-type echo-request -j ACCEPT -A INPUT -p icmp --icmp-type time-exceeded -j ACCEPT -A INPUT -i lo -j ACCEPT -A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT COMMIT
一般在多网卡的网络访问关系中我们通常根据目标 IP 地址段来添加静态路由 (static-routes),在主机系统配置层面这个需求一般都比较简单也不需要使用非常复杂的命令,说实话如果不是因为开发测试中心同事的乱入启发,我也不会发现还有策略路由这样一种灵活通用的配置方法来实现 Linux 多网卡多路由的设定,灰常感谢。
# 使用 ip route 命令和 route 命令类似 add 增加路由 del 删除路由 via 网关出口 IP 地址 dev 网关出口 物理设备名
# 添加路由 ip route add 192.168.0.0/24 via 192.168.0.1 ip route add 192.168.1.1 dev 192.168.0.1 # 删除路由 ip route del 192.168.0.0/24 via 192.168.0.1 # 增加默认路由 ip route add default via 192.168.0.1 dev eth0
# 在 / etc/sysconfig/static-routes 文件里添加如下内容 (没有 static-routes 的话就手动建立一个这样的文件) any net 192.168.3.0/24 gw 192.168.3.254 any net 10.250.228.128 netmask 255.255.255.192 gw 10.250.228.129
# 如果是生产系统可以考虑暂时不重启服务避免网络中断 service network restart
策略性是指对于 IP 包的路由是以网络管理员根据需要定下的一些策略为主要依据进行路由的。例如我们可以有这样的策略:“所有来直自网 A 的包,选择 X 路径;其他选择 Y 路径”,或者是 “所有 TOS 为 A 的包选择路径 F;其他选者路径 K”。 Cisco 的网络操作系统 (Cisco IOS) 从 11.0 开始就采用新的策略性路由机制。而 Linux 是在内核 2.1 开始采用策略性路由机制的。策略性路由机制与传统的路由算法相比主要是引入了多路由表以及规则的概念。
# 清空 net_192 路由表 ip route flush table net_192 # 添加一个路由规则到 net_192 表,这条规则是 net_192 这个路由表中数据包默认使用源 IP 172.31.192.201 通过 ens4f0 走网关 172.31.192.254 ip route add default via 172.31.192.254 dev ens4f0 src 172.31.192.201 table net_192 # 来自 172.31.192.201 的数据包,使用 net_192 路由表的路由规则 ip rule add from 172.31.192.201 table net_192
# 清空 net_196 路由表 ip route flush table net_196 # 添加一个路由规则到 net_196 表,这条规则是 net_196 这个路由表中数据包默认使用源 IP 172.31.196.1 通过 ens9f0 走网关 172.31.196.254 ip route add default via 172.31.196.254 dev ens9f0 src 172.31.196.1 table net_196 # 来自 172.31.196.1 的数据包,使用 net_196 路由表的路由规则 ip rule add from 172.31.196.1 table net_196
# 添加默认网关 route add default gw 172.31.192.254
# 如果需要自启动生效可以写进配置文件也可以加入 rc.local vi /etc/rc.local
ip route flush table net_192 ip route add default via 172.31.192.254 dev ens4f0 src 172.31.192.201 table net_192 ip rule add from 172.31.192.201 table net_192 ip route flush table net_196 ip route add default via 172.31.196.254 dev ens9f0 src 172.31.196.1 table net_196 ip rule add from 172.31.196.1 table net_196 route add default gw 172.31.192.254
# 查看路由表 route -n
Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 169.254.0.0 0.0.0.0 255.255.0.0 U 1006 0 0 ens9f0 169.254.0.0 0.0.0.0 255.255.0.0 U 1008 0 0 ens4f0 169.254.0.0 0.0.0.0 255.255.0.0 U 1014 0 0 br-ex 169.254.0.0 0.0.0.0 255.255.0.0 U 1015 0 0 br-int 172.31.192.0 0.0.0.0 255.255.255.0 U 0 0 0 ens4f0 172.31.196.0 0.0.0.0 255.255.255.0 U 0 0 0 ens9f0
# change anything if you need vi /etc/grafana/grafana.ini 30 [server] 31 # Protocol (http, https, socket) 32 ;protocol = http 33 34 # The ip address to bind to, empty will bind to all interfaces 35 ;http_addr = 36 37 # The http port to use 38 ;http_port = 3000 39 40 # The public facing domain name used to access grafana from a browser 41 ;domain = localhost
# start and enable grafana sudo systemctl start grafana-server sudo systemctl enable grafana-server sudo systemctl status grafana-server
# test http://<ip>:3000 admin/admin
# 添加数据源 安装很简单,之后需要配置数据源比如 InfluxDB/Zabbix API 等才能发挥真正的作用
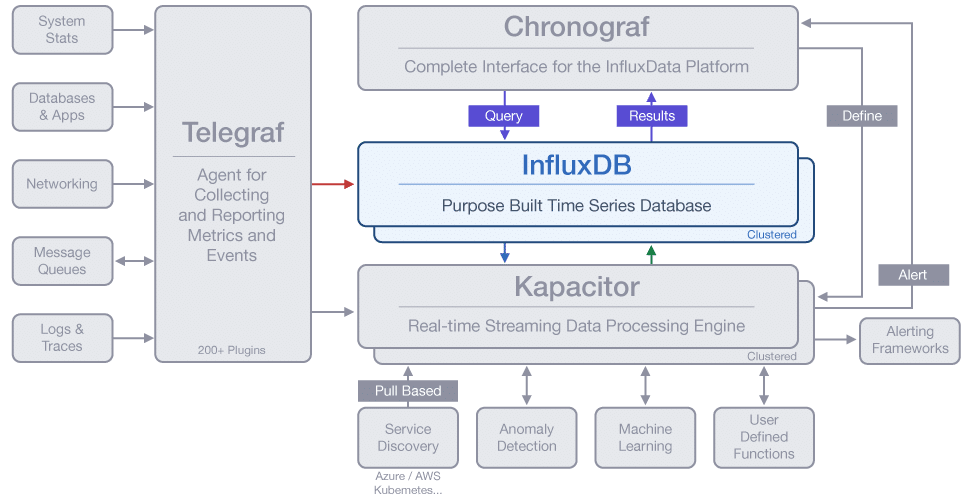
InfluxDB is the Time Series Database in the TICK Stack
InfluxData’s TICK Stack is built around InfluxDB to handle massive amounts of time-stamped information. This time series database provides support for your metrics analysis needs, from DevOps Monitoring, IoT Sensor data, and Real-Time Analytics. Users can adapt their SQL skills with InfluxQL, so they can get up to speed on this time series database.
OTP supports a set of release handling instructions that are used when creating .appup files. The release handler understands a subset of these, the low-level instructions. To make it easier for the user, there are also a number of high-level instructions, which are translated to low-level instructions by systools:make_relup.
{_From, Tag, get_modules} -> reply(Tag, get_modules(MSL)), loop(Parent, ServerName, MSL, Debug, false); ... %% Message from the release_handler. %% The list of modules got to be a set, i.e. no duplicate elements! get_modules(MSL) -> Mods = [Handler#handler.module || Handler <- MSL], ordsets:to_list(ordsets:from_list(Mods)).