前言
整理了 Golang 面试用的笔记,仅供参考
扩展阅读
本文结构:
1 | └──计算机基础 |
参考资料:笔试面试知识整理、Golang 面试题解析、Go面试题答案与解析
这篇文章的内容力大多一笔带过,细节上我参考的书籍有:
- 计算机网络:《计算计网络(谢仁希)》、《图解TCP/IP》、《TCP/IP 卷1: 协议》、《自顶向下方法》
- 数据结构:《数据结构与算法分析:C语言描述》
- 算法:《算法:C语言实现》
- 操作系统:《现代操作系统》
计算机网络

- TCP / UDP 传输层:端到端的服务
- IP 网络层:点到点的服务
HTTP 协议
请求报文
1 | <method> <request-URL> <version> # 状态行 # 状态行 |
HTTP 协议不限制 GET URL 长度,但浏览器限制字符数(Chrome 8K)& 也不限制 POST 资源大小
- GET:查
- 安全的:获取信息,非修改信息。一般不会产生副作用
- 幂等的:同一 URL 多个请求返回同一结果
- POST:改,服务端通过请求 header 的 Content-Type 字段解析实体数据。提交数据的方式:
- application/x-www-form-urlencoded:浏览器原生的 form 表单,提交的数据按 url 编码,Ajax大多默认使用
- form_data:表单文件上传
- application/json:API 使用较多
响应报文
状态行:协议版本、状态码、状态描述
1: Informational
- 100 continue:POST 提交数据大于 100KB 时候发的第一个请求,允许上传则返回 100
2:Success
- 200 OK:请求被成功处理,GET 返回资源、POST 返回对请求处理的结果
- 204 No Content:请求处理完毕,但不返回响应体,客户端页面不刷新
3:Redirection
301 Moved Permanently:永久重定向,资源分配了新的 URI,处理:
- HEAD:响应头的
Location指明新的 URI - GET:
Location指明新 URI & 在响应体中附上 URI
- HEAD:响应头的
302 Moved Temporarily:临时性重定向,希望用户本次能访问新的 URI。重定向后的请求方法不变
303 See Other:请求资源有另一个 URI,重定向后的方法变为 GET 获取新 URI
注意: 很多浏览器将 303 理解为 302,直接使用 GET 请求
Location中的 URI304 Not Modified:请求头中带有
If-Modified、If-Match,自从上次请求后资源并未更新,则不发送响应体。
4:Client Error
400 Bad Request:请求报文有语法错误
401 Unauthorized:请求需要有 HTTP 认证(nginx 的 auth_basic),返回 401 时头部中
www-authenticate指明认证方式,再次请求时也需带上authorization认证信息403 Forbidden:访问被拒绝,响应实体中可说明原因
404 Not Found:请求资源不存在、403 不想说明原因
5:Server Error
- 500 Internel Error:服务器处理请求出错
- 502 Bad Gateway: 服务器作为代理,从 upstream 收到无效响应
- 503 Server Unavailable:服务器暂时无法处理请求,恢复时间在
Retry-After
Conditional Get (条件 GET)
用户访问过该网页,再次访问。
GET 头部带有 If-Modified-Since:,若响应 304,则直接使用浏览器的缓存。否则返回正常实体
持久连接
HTTP 1.0 中:客户端请求头添加 Connection: Keep-alive,服务端同样在响应头中添加,保持连接
HTTP 1.1 中:默认所有连接都是长连接,添加 Connection: Close 才关闭,设置
Keep-Alive: timeout=5, max=100:长连接保持 5s,最多接收 100 次请求后断开- 注意:
Keep-Alive连接也是无状态的 - 传输结束的条件:传输的数据达到 Content-Length
HTTP Pipelining 管线化
批量提交 HTTP 请求,不排队等待响应才发送下一个请求:请求1 -> 响应1 -> 请求2 -> 响应2 -> 请求3 -> 响应3 变为 请求1 -> 请求2 -> 请求3 -> 响应1 -> 响应2 -> 响应3
- 管线化机制仅 HTTP1.1 支持
- 只支持 GET、POST
HTTP1.0 中发下一个请求前,必须等待响应。
会话追踪
HTTP 请求是无状态的协议,不会保存客户端信息,实现:
cookie
- 服务端发送给客户端的一小段信息,客户端每次请求都会带上,在有效期内识别身份。
- 分为保存在浏览器的临时 cookie 和保存在内存的永久 cookie
- 可被禁用
session
- 服务端创建 session 对象并用 sessionID 标识,将 sessionID 放到 cookie 中,发送给客户端
- cookie 被禁用,session 也会生效
token(重写 URL)
- 在 URL 中添加标识每个用户的 token(cookie 被禁用时,将 sessionID 重写到 URL 中)
HTTP 安全
CSRF 跨站请求伪造:攻击者知道所有参数、构造合法请求
伪造成其他用户,发起请求:如拼接恶意链接给其他用户点击。防范:
- 关键操作限制 POST
- 合适的使用验证码
- 添加 token:发起请求时添加附加的 token 参数,值随机。服务端做验证
- header refer:外部来源可拒绝请求
XSS 跨站脚本攻击:在客户端不知情的情况下运行 js 脚本。防范:
- 过滤和转义用户的输入内容:
htmlspecialchars() - 限制参数类型
- 文件上传做大小、类型限制
TCP 协议
特点
- 面向连接、可靠、字节流服务:有 TCP 缓冲,可切割较长数据块、累积较短数据块。与 UDP 每次数据报不同
- 校验和、确认和重传机制来保证可靠传输
- 动态改变滑动窗口来控制流量
- 一对一的通信,不能用于多播个广播
应用:HTTP、FTP、SMTP、SSH(数据准确性要求高)
优点:稳定可靠
缺点:慢、效率低、占资源多、易攻击(DDOS)
三次握手 Three-way Handshake
客户端执行 connect() 主动连接:
1 | A:听得到吗? |
理解:传输的信道不是绝对可靠的。为了不可靠的信道上可靠的传输信息,最少要进行三次通信。
TCP Flags 标志位:
1 | SYN:synchronous 建立连接 |
- SYN = 1 & ACK = 0:请求连接报文
- SYN = 1 & ACK = 1:同意建立连接的响应报文
过程:

第一次握手:客户端请求建立连接
SYN = 1,Seq = x,进入 SYN_SEND 状态,等待服务端应答
第二次握手:服务器允许建立连接
SYN = 1,ACK = x+1,Seq = y,进入 SYNC_RCVD 状态,等待客户端确认
第三次握手:客户端确认建立连接
ACK = y + 1,连接建立。双方进入 ESTABLIASHED 状态
四次挥手 Four-way handshake
服务端和客户端均可主动断开连接:服务端、客户端均需确认对方无数据再发送
第一次握手:无数据再发送,主动关闭连接
发送 FIN 报文,等待对法发送 ACK 报文,进入
FIN_WAIT_1状态第二次握手:同意关闭连接
发送 ACK 报文确认可关闭,并将未发送完毕的数据推送给对方
第三次握手:请求对方关闭连接
发送 FIN 报文,等待 ACK 报文
第四次握手:关闭
发送 ACK,进入
TIME_WAIT状态,过 2 MSL(最大分段生存时间)未收到重传信息,直接关闭。
注意: 中间直接发送 ACK + FIN,则主动方会直接跳过 FIN_WAIT_2 状态
TCP Keep-Alive 机制(心跳包)
数据交互完毕后,一方主动释放连接。但出现意外时,TCP 连接不能及时释放,导致要维护很多半打开的连接。
实现:定时(半秒等)给对方发一个探测包,若收到 ACK 则认为连接存活,若 重试一定次数 都没收到回应则直接丢弃该 TCP 连接。
在我的 B 站直播间数据爬虫 抓取时,就需要每隔半分钟给 B 站的弹幕服务器发一个心跳包,否则连接会在一分钟后断开。
UDP 协议
特点
- 不可靠:没有确认、超时重传、序列号机制:UDP 数据报不保证能送达、不保证数据报的顺序
- 无需建立连接:创建 UDP 连接前无需握手创建连接
- 一次发送一个报文,给定报文长度:过长 IP 层会分片
- 支持多播和广播
应用:DNS、流媒体(速度要求 > 质量要求)
优点:快、比 TCP 稍安全
缺点:不可靠、不稳定
| TCP | UDP | |
|---|---|---|
| 报文 | 面向字节流 | 面向报文 |
| 双工性 | 全双工 | 一对一、一对多、多对一、多对多 |
| 流量控制 | 滑动窗口 | 无 |
| 拥塞控制 | 快重传、快恢复 | 无 |
| 传输速度 | 慢 | 快 |
IP 协议
地址分类
IPv4 用点分十进制表示,IP 地址 = 网络地址 + 主机地址(层次)
全零 0.0.0.0 :本主机、全一:255.255.255.255 当前子网的广播地址

A 类:8 - 1(0) = 7 位网络号
- 主机A的地址为:58.1.2.3/8,前面58位于1~127之间,所以这是一个A类地址.
- 跟主机A位于同一个网络中的IP地址有 : 58.0.0.1 ~ 58.255.255.254,一共有 2^24-2个
- 不包括:58.0.0.0(网络地址)跟58.255.255.255(广播地址)
B 类:16 - 2(10) = 14 位网络号
C 类:24 - 3(110) = 21 位网络号
子网掩码
用子网掩码划分一个 IP 的网络地址和主机地址。
1 | IP & 子网掩码 = 网络地址 |
192.168.1.1/24 是 192.168.1.1/255.255.255.0 的简写,前 24 位为网络号
子网划分:将大的整体网络划为小的子网络
Socket 编程
socket:三元组(IP 地址、协议、端口号)标识网络中唯一的进程,在 unix 中是文件
socket 使用了门面 Facade 模式:外部与内部的通信必须经过 facade
socket 隐藏了 TCP/IP 细节,开放交互接口。有:
1 | socket() // 创建套接字 |
搭建简单的 Server:
- 等待连接
- 建立连接
- 接收请求:读取 HTTP 请求报文
- 处理请求:访问资源(文件)
- 构建响应:创建 HTTP 响应报文
- 发送响应
数据结构
1 | └── 数据结构 |
参考资料:常见数据结构及其多种实现的可视化
数组 Array
元素在内存中连续存放。每个元素占用内存相同,可通过下标算出元素位置快速访问
优点:访问快 O(1)
缺点:增加、删除元素需要移动大量元素,慢 O(N)
场景:快速访问元素,很少插入和删除元素
| 数组 | 链表 | |
|---|---|---|
| 内存分配、元素存储位置 | 静态分配内存(栈,系统自动分配) | 动态分配内存(堆,申请和管理麻烦) |
| 栈 | 堆 | |
| 分配方式 | 系统自动分配、速度快 | 自己申请和管理、new 慢 |
| 大小 | 编译时确定,具体值 | 是不连续的内存区域 |
链表 Linked List
元素在内存中不是连续存放。元素间通过指向指针联系在一起,访问元素必须从第一个元素开始遍历查找
优点:插入、删除元素只需改变指针,快 O(1)
缺点:访问慢 O(N)
场景:经常插入、删除元素
分类
- 单向链表:节点仅指向下一节点,最后一个节点指向 nil
- 双向链表:每个节点有 2 个指针
pre和next,最后一个节点的next指向 nil - 循环链表:单链表 + 最后一个节点指向第一个节点
时间复杂度
- 查找:
O(N) - 插入、移除:
O(1)
栈 Stack
元素遵循后进先出(LIFO)原则。元素仅在表尾(栈顶)进行插入(入栈 push)、删除(出栈 pop)
实现
- 单链表实现:保存头节点的指针,在头节点前入栈、头节点上出栈
- 数组实现:直接操作数组最后一个元素,可能出现数组溢出:
- 空栈(空数组)上
pop() - 满栈(满数组)上
push(),加倍数组大小
- 空栈(空数组)上
时间复杂度
- 查找:O(N)
- 插入、删除:O(1)
队列
元素遵循先进先出(FIFO)原则。元素在一端插入(进队列 enqueue)、另一端删除(出队列 dequeue)
出队列元素是在队列中存在时间最长的元素。
实现
- 单链表实现:保存指向首尾节点的指针,从链表尾进队列,链表头出队列
- 数组实现:修改
arr[0]进队列,修改arr[len - 1]出队列
时间复杂度
- 查找:O(N)
- 插入、删除:O(1)
哈希表
散列表:根据 key 键值直接访问数据的内存地址
hash(data) = key:hash() 是一类算法,处理任意长度的 data,得到定长的 key 值,过程不可逆。
若 data 是数据集,则 key 也是数据集,将 keys 与原始数据一一映射就得到哈希表,即 M[key] = data
二叉树

- 满二叉树:深度为 k 且有 2^k -1 个节点的二叉树
- 完全二叉树:最后一层只缺右边节点,其它层节点数已为最大值
遍历方式(栈实现较好)
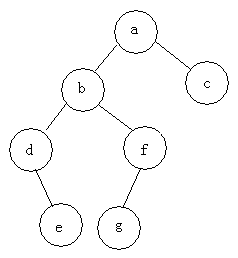
- 前序遍历:根 -> 左 -> 右:abdefgc
- 中序遍历:左 -> 根 -> 右:debgfac
- 后序遍历:左 -> 右 ->根:edgfbac
二叉搜索树
性质:左子节点均小于根节点、右子节点均大于根节点
复杂度
- 搜索:
O(log(n)) - 插入和删除:
O(log(n))
算法
1 | └── 算法 |
参考资料:常见算法的过程可视化、常见算法的 Go 实现
排序

数据大小 n,好的复杂度 O(logN),坏的 O(N2)
应用场景
- n 较小:直接插入排序
- 基本有序:冒泡排序、直接插入
- n 较大:快速排序、归并排序、堆排序等 O(NlogN)
交换排序一:冒泡排序

过程
- 比较相邻元素,前大于后就交换。
- 遍历操作第 1~N 个元素,此时 第 N 个元素最大。
- 遍历操作 1~N-1,重复遍历并比较、交换。…
- 嵌套遍历结束即完成排序。
优化
- 设置 flag,发生交换设为 true,某趟提前排序完毕则为 false,直接退出。
- 记录每轮最后发生排序的位置,下轮遍历到此处即可。
分析
| 情况 | 复杂度 |
|---|---|
| 最佳情况:已有序,全遍历 1 次 | O(N) |
| 最坏情况:反序,全遍历 N 次 | O(N^2) |
| 平均情况 | O(N^2) |
交换排序二:快速排序

过程
- 选取基准:从数组中选一个数(第一个)作为基准
- 分区:遍历数组,比基准更小的值放在基准前边、更大的在后边
- 递归:递归的在分区后的数组中,再选基准、分区
分析
| 情况 | 复杂度 |
|---|---|
| 最佳 | O(logN) |
| 最坏(数组反序、数组元素全部相同) | O(N^2) |
| 平均 | O(logN) |
选择排序一:简单选择排序

过程
- 遍历第 1 次:找出最小的元素置于第 1 位。…
- 遍历第 N-1 次:排序完毕
分析
| 情况 | 复杂度 |
|---|---|
| 最佳、最差、平均 | O(N^2) |
选择排序二:堆排序
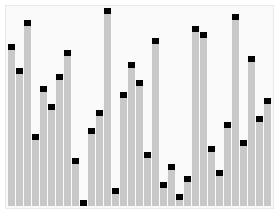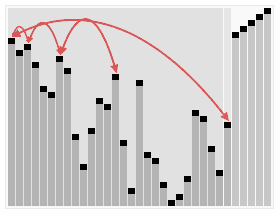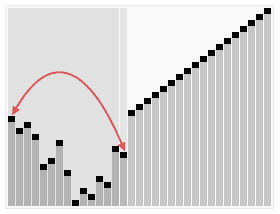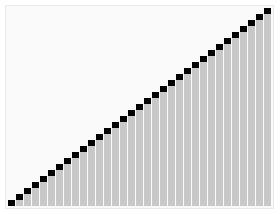
过程
- 将无序的数组构建成二叉树
- 二叉树整理为堆(完全二叉树)
- 输出根结点,再次整理堆输出根结点…
分析
| 情况 | 复杂度 |
|---|---|
| 最佳、最差、平均 | O(logN) |
插入排序一:直接插入排序

过程
- 第一个元素(认为已排序好)
- 从第二个元素开始,往后选择元素向前遍历,找到合适的位置插入
- 遍历到最后一个位置,排序完毕
分析
| 情况 | 复杂度 |
|---|---|
| 最佳(数组升序) | O(N) |
| 最坏(数组反序) | O(N^2) |
| 平均 | O(N^2) |
插入排序二:希尔排序

过程:选择一个固定(动态)的步长,对步长内的元素进行直接插入排序
分析
| 情况 | 复杂度 |
|---|---|
| 最佳、最坏、平均(都要步长分割、遍历) | O(NlogN) |
归并排序

过程
- 将长度为 N 的序数组分为 N / 2 的子数组
- 递归划分子数组,子数组内部排序
分析
| 情况 | 复杂度 |
|---|---|
| 最佳 | O(N) |
| 最坏 | O(NlogN) |
| 平均 | O(NlogN) |
基数排序(非比较)

过程
- 获取数组中最大值的位数 b
- 从 1 ~ b 遍历组合位数相同的元素
分析
| 情况 | 复杂度 |
|---|---|
| 最佳、最坏、平均 | O(N * b) |
查找
无序查找:顺序查找
- 顺序扫描序列,依次比较值
- 复杂度:O(N)
有序查找(无序序列需要提前排序)
二分查找(折半查找)
- 找到中间节点比较值,相等则查找到,更小则继续对左边折半查找,更大则向右边
- 查找比对点:
mid = (low + high) / 2或mid = low + (high - low) / 2 - 复杂度:比较次数,O(log2 N)
插值查找
- 动态的改进二分查找的查找点,使其更接近区间
- 查找对比点:
mid = low + (key - arr[low]) / (arr[high] - arr[low]) * (high - low) - 复杂度:O(log2(log2N))
二叉查找树
- 中序遍历获得排序好的数组
- 复杂度:一般 O(log2N),最坏情况 单支树 O(N)
平衡二叉查找树(AVL 树)
- 任何节点的 2 棵子树,高度差最多为 1
- 平衡:根结点到任意一个叶子节点,距离都相等
操作系统
体系结构
机器码:最高位 0 为正、1 为 负
原码:符号位 + 真值绝对值的二进制
反码:正数反码就是本身、负数除符号位外取反
补码:正数补码就是本身、负数除符号位外取反 + 1
1
2[+1] = [00000001]原 = [00000001]反 = [00000001]补
[-1] = [10000001]原 = [11111110]反 = [11111111]补1 byte = 8 bits,1 word = 2 byte(16位)= 4 byte(32位机)& 字是计算机数据处理和运算的单位
字节序:占用内存超过 1 byte 的数据在内存中的存放顺序
小端字节序:低字节数据放在内存低地址
大端字节序:低字节数据放在内存高地址(符合阅读习惯,网络中数据传输的协议,即网络字节序)
B 站直播数据抓取 中,请求数据的打包格式就是大端字节序,否则连接到弹幕服务器。1
2
3
4
5
6
7
8
9
10
11
12
13
14
150x12345678 的存储:
Big Endian
低地址 高地址
---------------------------------------------------->
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 12 | 34 | 56 | 78 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Little Endian
低地址 高地址
---------------------------------------------------->
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 78 | 56 | 34 | 12 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
基础
操作系统功能:文件管理、存储管理、输入输出管理、作业管理、进程管理
中断
- CPU 暂停执行当前程序,去执行中断程序
- 中断的优先级指明处理的紧急程度,如:
机器错误 > 时钟 > 磁盘 > 网络设备 > 终端 > 软件中断
系统调用
- 2 个级别:核心态、用户态
- 程序执行一般在 user model,需要使用操作系统服务(创建、读写文件),请求切换到 kernel model 执行
- 核心态能存取用户、内核的指令和数据,用户态只能存取用户自己的指令和数据
中断和系统调用的关系:程序申请核心态时,将产生一个软件中断,系统将处理
并发多任务
多道程序:程序运行, CPU 空闲时(等待 IO),此时 CPU 去运行其他程序
分时系统:改进后的多道程序,程序运行一段时间后会主动让出 CPU
多任务系统:操作系统从底层接管所有硬件资源,程序以进程运行,程序运行超时会被强制暂停
进程
运行中的程序
4 个地址空间
- 文本域:要执行的代码
- 数据域:存放变量、程序执行期间动态分配的内存
- 堆栈:存放本地变量和指令
3 种状态
- 等待态:IO
- 就绪态:等待系统分配 CPU 运行
- 运行态:占用 CPU 正在处理
4 种进程间通信
- 消息传递:pipe管道
- 同步:信号量、读写锁
- 内存共享
- 远程过程调用:RPC
死锁:多个进程因循环等待资源而都无法执行
线程
轻量级进程
- 解决问题:很多不同的进程需要共享同样的资源(文件),切换进程的成本很高
- 是可以独立运行的单位,切换快速、开销小 & 可并发执行
- 共享进程的资源:在同一进程中的线程因为有相应的地址空间,可以共享进程已打开的文件、定时器等
协程
- 微线程,coroutine:用户级的线程
- 线程是抢占式调度、协程是协同式调度,避免无意义的抢占,但是调度由用户决定
IO 多路复用
内核发现某个进程指定的 IO 准备读取,就会通知该进程,如客户端处理多个描述符时,大大减小创建和维护的开销。
并发与并行
- 并发:多个操作可在重叠的时间运行
- 并行:同一时刻有多条指令在执行,多核是并行的前提。
数据库
事务:一系列 SQL 集合
ACID 特性
- 原子性 automatic:事务是原子工作单位,要么全部执行、要么全部不执行
- 一致性 consistency:数据库通过事务完成状态转变
- 隔离性 isolation:事务提交前,对数据的影响是不可见的
- 持久性 duration:事务完成后,对数据的影响是持久的
4 种隔离级别
- 脏读:一个事务读取了另一个事务尚未提交的修改
- 非重复读:一个事务对同一行数据读取两次,得到不同结果
- 幻读:事务在操作过程中进行了两次查询,第二次的结果包含了第一次未出现的新数据
- 丢失修改:当两个事务更新相同的数据源,第一个事务提交,第二个撤销。那么第一个也要撤销
3 种实现隔离的锁
- 共享锁 S 锁:只读 SELECT 操作,锁定共享资源,阻止其他用户写数据
- 更新锁 U 锁:阻止其他用户更新数据
- 独占锁 X 锁:一次只能有一个独占锁占用一个资源,阻止添加其他所有锁。有效防止脏读
索引
优点
- 大大加快检索速度
- 加快表之间的关联
- 唯一性索引 UNIQUE:保证行数据的唯一性
缺点
- 创建和维护消耗时间和物理空间
场景
- 用在经常需要连接的字段:如外键,加快连接速度
- 用在经常需要排序的字段:索引已排序,直接利用,加快排序时间
OOP
三个基本特征:封装、继承、多态
封装
- 提取对象的特征,抽象成类。
- 外部只能访问 public 的属性和方法。private 的属性和方法内部调用,设置 getter、setter 开放接口允许外部访问和修改私有数据,protected 的数据和方法子类继承和调用
继承:使用现有类的所有功能。
多态:子类覆盖父类的同名方法
Golang 面试题
问答类
1. 在 Go 中如何使用多行字符串?
使用反引号 `` 来包含多行字串,或使用 + 来连接多行字符串(注意换行会包含\n,缩进会包含 \t,空格没有转义符):
1 | func main() { |
2. 如何获取命令行的参数?
有两种方法:
使用 os 库,如:
1 | func main() { |
可以看出 os.Args 接收到的参数是 string slice,元素分别是运行的程序名、多个参数值:

使用 flag 库,步骤:
- 定义各个参数的类型、名字、默认值与提示信息
- 解析
- 获取参数值
1 | func main() { |
注意上边获取参数值的两种方式,使用时也有所不同:
1 | func Int(name string, value string, usage string) *string // 返回地址 |

3. 如何在不输出的情况下格式化字符串?
使用 func Sprintf(format string, a ...interface{}) string 即可,常用在手动组合 SQL 语句上:
1 | func main() { |
4. 如何交换两个变量的值?
直接使用元组(tuple)赋值即可:
1 | a, b = b, a |
注意元组赋值是对应有序赋值的:
1 | a, b, c = b, c, a // 交换三个变量的值 |
5. 如何复制 slice、map 和 interface 的值?
slice:
1 | func main() { |
- 直接赋值, 底层数组将不会更新:

使用
copy()
返回值是min(len(names), len(src)),只会拷贝前两个元素,pNames 的值显示 names 的底层数组已被覆盖更新:
map:
最简单的方法,遍历所有 key:
1 | func main() { |
interface:
Go 中没有内建的函数来直接拷贝 interface 的值,也不能直接赋值。如 2 个 struct 的字段完全一致,可以使用强制类型转换或反射来赋值。
参考:关于结构体复制问题、Copying Interface Values In Go
6. 下边两种 slice 的声明有何不同?哪种更好?
1 | var nums []int |
第一种如果不使用 nums,就不会为其分配内存,更好(不使用编译也不会通过)。
写出程序运行输出的内容
1. 考察多个 defer 与 panic 的执行顺序
1 | func main() { |
defer 可以类比为析构函数,多个 defer 本身的执行是栈 LIFO 先进后出的顺序,代码抛出的 panic 如果在所有 defer 中都不使用 recover 恢复,则直接退出程序。
如果手动使用 os.Exit() 退出,则 defer 不执行。

2. 考察 defer 与 return 的执行顺序
1 | func main() { |
注意 return var 会分为三步执行:
return 语句为 var 赋值
- 匿名返回值函数:先声明,再赋值
- 有名返回值函数:直接赋值
检查是否存在 defer 语句:逆序执行多条 defer,有名返回函数可能会再次修改 var
真正返回 var 到调用处

3. 考察 goroutine 的传值方式
1 | func main() { |
第一个 for 循环:以极快的速度分配完 5 个 goroutine,此时 i 的值为 5,gouroutine 得到的 i 都是 5
第二个 for 循环:每次都会将 i 的值拷贝一份传给 goroutine,得到的 i 不同,输出不同

4. 考察 defer 参数的计算时机
1 | func main() { |
defer 语句会计算好 func 的参数,再放入执行栈中。
注意第 7 行:四个 defer func 的参数此时已是确定值,不再对 defer 中的 b 造成影响。

5. 考察 Go 的组合
1 | type People struct{} |
第 13 行: Teacher 通过嵌入 People 来获取了 ShowA() 和 showB()
第 16 行:Teacher 实现并覆盖了 showB()
第 24 行:调用未覆盖的 showA(),因为它的 receiver 依旧是 People,相当于 People 调用
